| [えでぃっとはうすのときど記] |
不可解な文字化け・その2 先日の不可解な文字化けについて、なかなか原因までにはたどりつかないが、とりあえず、どのように文字化けしたのかについては、少し見えてきた。 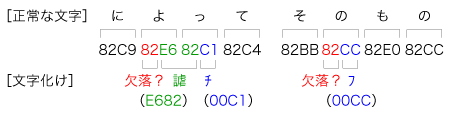 ようするに「よ」と「の」の1バイト目の「82」が何らかの理由で欠落したために、以下のコードの組み合わせがずれたものが、今回の文字化けだったようだ。 (記:2004/09/05) |
[][ときど記]
| [えでぃっとはうすのときど記] |
不可解な文字化け・その2 先日の不可解な文字化けについて、なかなか原因までにはたどりつかないが、とりあえず、どのように文字化けしたのかについては、少し見えてきた。 ようするに「よ」と「の」の1バイト目の「82」が何らかの理由で欠落したために、以下のコードの組み合わせがずれたものが、今回の文字化けだったようだ。 (記:2004/09/05) |
[][ときど記]